Shared Memory Poll Transport
This document describes the shared memory poll transport in RaimaDB. For the following discussion we assume a client running on a micro-controller on an ARM M-Core and a server running under Linux on an ARM A-Core, possibly on the same physical die. This transport is enabled using the TFS URI ‘tfs-shm-poll://0’ and listen on ‘shm_poll’.
Overview of the Transport Layer
RaimaDB uses communication transports to connect and send messages from a RaimaDB client to a RaimaDB TFServer. A message consists of a request initiated from the client with a response from the server.
The request will generally fit within one communication packet between the client and the server. And the response from the server will also generally fit within one communication packet. If not, the request or response will be broken up into multiple packets.
The Shared Memory Poll Transport
One of the transport implementations is the shared memory poll transport that can be used where both the client and the server have access to some shared memory with full coherence between them. It requires a fixed-length memory buffer (64 bytes plus 32KB). This memory buffer may be accessed directly using physical memory addresses or it may be mapped into a virtual address space. These will be physical memory addresses in the case of the M-Core and memory mapped into virtual address space for the A-Core.
The memory buffer contains a header to store the communication status and the message packet being transferred to/from the server.
Header
The shared memory buffer is a 64 bytes header plus a 32KB message buffer. The most essential parts of the header are two message packet sizes.
Client Send Size
The first message packet size is size_to_tfs. This size communicates whether the client has something for the server or not. The client will set the size to a non-zero value, which means that the shared-memory buffer contains a message packet of that size for the server to read. When the server has read the whole message packet the server will set the size back to 0.
When the server sets this size to zero (0), it indicates to the client that it can write the next message packet into the buffer. If there is nothing more to write, the client will wait for the server to handle the request and send a response message packet back to the client.
Client Receive Size
The second packet size is size_from_tfs. This size communicates whether the server has something for the client or not. This works similarly to size_to_tfs except that the roles between the server and the client are switched.
Wasted CPU Cycles
For this shared memory poll transport, there are no other mechanisms between the client and the server. The client will write a message packet into the buffer, update the header size, and wait for a response. The client waits for the response by polling the header for a response from the server.
The client will thereby burn CPU cycles while waiting unless it is preempted by another task/thread. These wasted CPU cycles may not be desirable. However, in the case of the client executing on an M-core CPU and the server executing on an A-core CPU the amount of time the client must wait is expected to be negligible. An A-core typically runs a couple of magnitudes faster than an M-core. Replacing this polling with another synchronization mechanism may therefore lower the overall system performance.
The server will likewise burn CPU cycles while waiting for a request from the client or clients. In the case of the server running on an A-core CPU the amount of time the server must wait is expected to be significant. The server will thereby either handle a request or wait for a request by polling unless the server blocks on a timer or otherwise is preempted. It is therefore expected to have CPU utilization close to 100%.
With other threads or processes communicating with the server the scenario described above may be more or less skewed. Tasks/threads on the M-core may end up waiting for a longer time due to other threads or processes holding database locks or a mutex being held on the server side to handle these requests. Increasing the load on the A-core may result in unacceptable performance on the M-core due to it spending too much time polling.
Transport Process
The shared memory buffers are mainly initialized by the server (TFS). The server will initialize the shared memory headers and write its UUID into the header of each communication channel. A client may already have written its UUID into the header or will later do so. Before a client can use a given channel the server must respond with the client's UUID. These UUIDS are written into distinct places in the header and any race condition between clients can therefore be resolved by the server. In the event that the server is restarted, dangling clients will discover that the server UUID has changed and return with an error instead of a normal return.
Communication between the client and the server on an RaimaDB message protocol level is always initiated by the client. The client will make a request with a message packet and the server processes that request and similarly responds with a message packet.
If the request to the server or the server’s response to the client does not fit in the memory buffer, the request will be broken up into smaller message packets. The receiver in the communications knows, based on the content, that additional information is required and will poll and process packets until the whole message has been received.
Concurrency
One database handle can be used by more than one thread at the same time with exactly the same TFS URI as long as a mutex is used to synchronize RaimaDB API calls between clients.
To avoid deadlock, hold a mutex for the whole duration database locks are held (from before the call to rdm_dbStartRead() or rdm_dbStartUpdate() until rdm_dbEnd() has returned).
Limit the number of other calls while database locks are held to ensure that deadlines are met. There is a tradeoff between per task/thread performance versus availability for database locks. Balancing this can be tricky. Holding database locks for too long may result in other tasks/threads timing out of their requests (eUNAVAILABLE/eTIMEOUT) or missing their deadlines. Setting the TIMEOUT option to ‘-1’ will prevent lock requests from timing out.
Locks need to be taken in particular orders to prevent deadlock. In general, read locks on a particular table can be held in parallel with other tasks/threads holding a read lock on the same table, while write locks need exclusive access to their tables. Requesting locks on multiple tables can result in dependencies between tasks/threads where one task/thread cannot continue until another task/thread has released their locks. One should therefore take measures to not have a cycle of cycles of such dependencies to prevent deadlocks.
Message protocol
The actual messaging protocol depends on the RaimaDB API being used and possibly also option parameters. Using the rdmrdm_client library or the rdmrdm library in combination with the rdmtfs_client library a session consists of a login message, followed by a number of other messages, and finalized with a logout message. Calling rdm_dbOpen() will result in two messages. One message to log in and one message to open the database. Similarly for rdm_dbClose() that will also result in two messages.
Using the rdmrdm library in combination with the rdmtfs_client library one RaimaDB API call may result in zero to many messages. RaimaDB API function calls for reading and navigation may result in a few or many messages to the TFS or no messages at all depending on how much is cashed on the client side. RaimaDB API function calls for updating rows will not result in any messages being sent to the TFS as those are being cached on the client side until the changes are committed (rdm_dbEnd()).
The following image depicts the shared-memory transport interaction with a simple row insert.
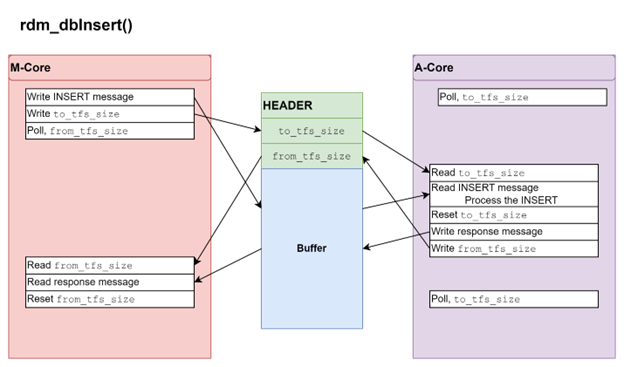
Transport channels
The message protocol in RaimaDB allows more than one client to share a transport channel as long as only one client is using it at a given time. Several clients can be logged in but they must synchronize their use of the channel. They will need to take turns by taking a mutex before RaimaDB API calls and hold the mutex until the call returns.
However, if the clients are running on bare metal without an OS or without a mutex implementation or it is otherwise undesirable to take a mutex, independent channels are needed. Independent channels can be specified using a TFS URIs ‘tfs-shm-poll://N’ where N is different numbers.
Using multiple channels requires the server to poll more than one channel and since each of these are served by separate threads even more CPU cycles are being wasted on the A-core.
Real Time OS and the Risk of Deadlocks
We have discussed concurrency and the risk of deadlocks in previous sections.
Under a real time OS the risk of deadlock is even greater. One task/thread may wait for a database lock to be granted while a lower priority task/thread has it. If the high priority task/thread is burning CPU cycles by polling, waiting for a replay from the server, the low priority task/thread may never be able to finish its work. The database lock held by the low priority task/thread will never be freed and we have a deadlock.
Because of the risk of a deadlock one can resort to always taking a mutex before acquiring a database lock and releasing it when the database lock is freed. This approach eliminates the deadlocks described above assuming we also acquire the mutex at a few other places. This also eliminates the need for multiple database handles. One database handle can therefore be shared between all the tasks/threads and we are back to the initial approach.
The observation here is that avoiding deadlocks can be tricky and it is not clear that using multiple database handles for the shared memory poll transport is beneficial under a real time OS.